Fix today. Protect forever.
Secure your devices with the #1 malware removal and protection software
Recurrent Neural Networks (RNNs) have gained popularity in recent years due to their ability to effectively model sequential data. These networks have been successfully applied in a wide range of tasks such as natural language processing, speech recognition, and time series prediction. However, one of the challenges in training RNNs is the issue of vanishing or exploding gradients, which can make it difficult for the network to learn long-range dependencies.
One potential solution to this problem is the use of gated architectures, which have been shown to be effective in mitigating the vanishing gradient problem in RNNs. Gated architectures, such as Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU), introduce gating mechanisms that control the flow of information within the network. These gates are able to selectively update and reset the hidden state of the network, allowing it to remember long-term dependencies while avoiding the vanishing gradient problem.
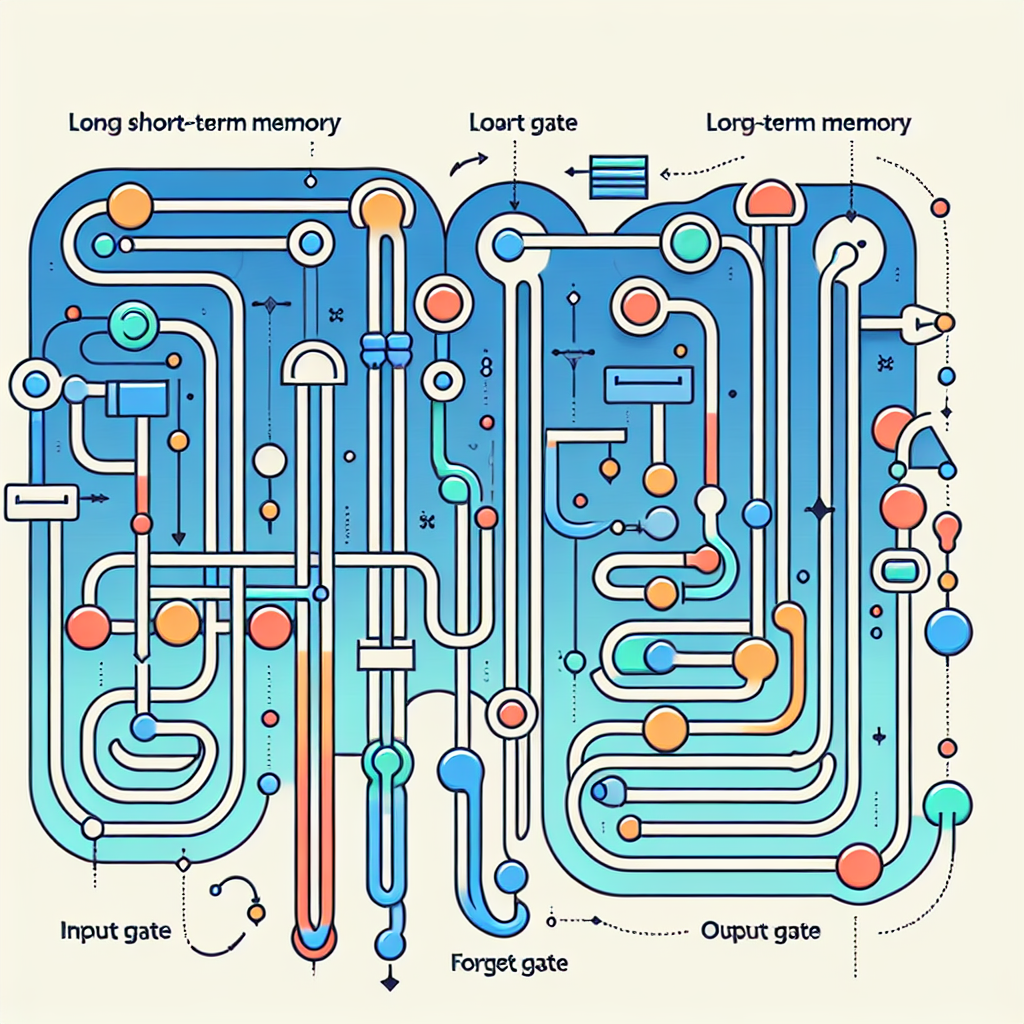
LSTM, in particular, has been widely used in various applications due to its ability to capture long-range dependencies in sequential data. The architecture of an LSTM cell consists of three gates – input gate, forget gate, and output gate – that control the flow of information in and out of the cell. By selectively updating the hidden state of the cell, LSTM is able to effectively model complex temporal dependencies in the data.
Similarly, GRU is another type of gated architecture that has been shown to perform well in sequential data tasks. GRU simplifies the architecture of LSTM by combining the input and forget gates into a single update gate, which helps reduce the computational complexity of the network. Despite its simpler design, GRU has been shown to achieve comparable performance to LSTM in many applications.
The effectiveness of gated architectures in RNNs lies in their ability to learn long-range dependencies while avoiding the vanishing gradient problem. By introducing gates that control the flow of information, these architectures are able to selectively update the hidden state of the network, allowing it to retain important information over long sequences. This makes gated architectures well-suited for tasks that involve modeling complex temporal dependencies, such as language modeling, speech recognition, and music generation.
In conclusion, gated architectures have shown great promise in unleashing the potential of RNNs by addressing the vanishing gradient problem and enabling the network to learn long-range dependencies. LSTM and GRU are two popular gated architectures that have been successfully applied in various applications, showcasing their effectiveness in modeling sequential data. As researchers continue to explore new architectures and techniques for improving RNNs, gated architectures are likely to play a key role in advancing the capabilities of these networks in the future.

#Unleashing #Potential #Gated #Architectures #Recurrent #Neural #Networks,recurrent neural networks: from simple to gated architectures