Your cart is currently empty!
Tag: Sequence

Building Sequence Generative Models with Recurrent Neural Networks
Recurrent Neural Networks (RNNs) have proven to be powerful tools for modeling sequential data. They have been used in a variety of applications such as natural language processing, speech recognition, and time series prediction. In recent years, researchers have been exploring the use of RNNs for generating sequences of data, such as text or music.Building Sequence Generative Models with RNNs involves training a neural network to learn the structure and patterns in a sequence of data, and then using this learned model to generate new sequences. This can be a challenging task, as it requires the network to capture the underlying dependencies and long-range correlations in the data.
One common approach to building sequence generative models with RNNs is to use a technique called “teacher forcing”. In this approach, the network is trained to predict the next element in the sequence given the previous elements. During training, the true sequence is fed into the network as input, allowing it to learn the correct sequence of predictions. However, during generation, the network is fed its own predictions as input, leading to a divergence from the true sequence. This can result in a loss of fidelity in the generated sequences.
Another approach to building sequence generative models with RNNs is to use techniques like Long Short-Term Memory (LSTM) or Gated Recurrent Units (GRUs). These architectures are designed to capture long-range dependencies in the data, making them well-suited for sequence generation tasks. By using these more sophisticated architectures, researchers have been able to generate more coherent and realistic sequences.
In addition to using more advanced architectures, researchers have also explored techniques like attention mechanisms and reinforcement learning to improve the performance of sequence generative models with RNNs. Attention mechanisms allow the network to focus on different parts of the input sequence, while reinforcement learning can be used to guide the generation process towards more desirable outcomes.
Overall, building sequence generative models with RNNs is a challenging but rewarding task. By leveraging the power of recurrent neural networks and exploring advanced techniques, researchers have been able to generate sequences of data that exhibit complex patterns and structures. As the field of deep learning continues to evolve, we can expect to see even more impressive results in the realm of sequence generation.
#Building #Sequence #Generative #Models #Recurrent #Neural #Networks,rnn
Enhancing Sequence Modeling with Recurrent Neural Networks
Recurrent Neural Networks (RNNs) have become a popular choice for sequence modeling tasks in the field of machine learning. These networks are designed to handle sequential data by maintaining a memory of past inputs, allowing them to capture dependencies and patterns within the data. However, there are challenges in training RNNs, such as vanishing gradients and difficulty in capturing long-term dependencies. In this article, we will explore how to enhance sequence modeling with RNNs.One way to improve the performance of RNNs is to use more advanced architectures, such as Long Short-Term Memory (LSTM) or Gated Recurrent Unit (GRU) networks. These architectures are designed to address the issue of vanishing gradients by introducing mechanisms that control the flow of information through the network. LSTM networks, for example, have a cell state that can store information over long periods of time, allowing them to capture long-term dependencies in the data.
Another way to enhance sequence modeling with RNNs is to use techniques such as attention mechanisms. Attention mechanisms allow the network to focus on different parts of the input sequence, giving more weight to relevant information. This can help improve the performance of the network, especially when dealing with long sequences or when there is important information scattered throughout the input.
Furthermore, incorporating regularization techniques can also help enhance the performance of RNNs. Techniques such as dropout, which randomly drops out units during training, can help prevent overfitting and improve the generalization of the model. Regularization techniques can also help address the issue of exploding gradients, which can occur when the gradients become too large during training.
In addition to using advanced architectures and regularization techniques, it is important to carefully tune hyperparameters and optimize the training process when working with RNNs. This includes choosing an appropriate learning rate, batch size, and number of training epochs, as well as monitoring the training process and adjusting the model accordingly.
In conclusion, enhancing sequence modeling with RNNs involves using advanced architectures, attention mechanisms, regularization techniques, and careful hyperparameter tuning. By incorporating these techniques and optimizing the training process, RNNs can effectively capture dependencies and patterns within sequential data, making them a powerful tool for a variety of machine learning tasks.
#Enhancing #Sequence #Modeling #Recurrent #Neural #Networks,rnn
Enhancing Sequence Learning with Gated Recurrent Neural Networks
Sequence learning is a fundamental task in machine learning that involves predicting the next element in a sequence given the previous elements. One popular approach to sequence learning is using Recurrent Neural Networks (RNNs), which are designed to handle sequential data by maintaining a hidden state that captures information about the past elements in the sequence.However, traditional RNNs can struggle to capture long-range dependencies in sequences, leading to difficulties in learning complex patterns. To address this issue, researchers have developed Gated Recurrent Neural Networks (GRNNs), which incorporate gating mechanisms to better regulate the flow of information through the network.
One of the key advantages of GRNNs is their ability to learn long-range dependencies more effectively than traditional RNNs. This is achieved through the use of gating units, such as the Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU), which control the flow of information by selectively updating and forgetting information in the hidden state.
The gating mechanisms in GRNNs enable the network to better retain important information over longer periods of time, making them well-suited for tasks that require modeling complex temporal dependencies, such as speech recognition, language translation, and music generation.
In addition to improving the learning of long-range dependencies, GRNNs also help address the issue of vanishing and exploding gradients that can occur in traditional RNNs. By controlling the flow of information through the network, the gating mechanisms in GRNNs help mitigate these gradient-related problems, leading to more stable and efficient training.
Furthermore, GRNNs have been shown to outperform traditional RNNs on a wide range of sequence learning tasks, including language modeling, machine translation, and speech recognition. Their ability to capture long-range dependencies and better regulate the flow of information through the network makes them a powerful tool for modeling sequential data.
In conclusion, Gated Recurrent Neural Networks offer a significant improvement over traditional RNNs for sequence learning tasks. Their gating mechanisms enable them to better capture long-range dependencies, mitigate gradient-related issues, and outperform traditional RNNs on a variety of sequence learning tasks. As the field of machine learning continues to advance, GRNNs are likely to play an increasingly important role in modeling sequential data and advancing the state-of-the-art in various applications.
#Enhancing #Sequence #Learning #Gated #Recurrent #Neural #Networks,recurrent neural networks: from simple to gated architectures
How LSTM Networks are Revolutionizing Sequence Prediction
Sequence prediction is a crucial task in many fields such as natural language processing, time series analysis, and speech recognition. Traditional methods for sequence prediction, such as Hidden Markov Models and Recurrent Neural Networks (RNNs), have limitations in capturing long-term dependencies in the data. However, Long Short-Term Memory (LSTM) networks have emerged as a game-changer in sequence prediction, revolutionizing the way we approach this problem.LSTM networks are a type of RNN that have additional mechanisms to prevent the vanishing or exploding gradient problem that often occurs during training. This allows LSTM networks to effectively capture long-term dependencies in the data, making them ideal for sequence prediction tasks. The key innovation of LSTM networks is their ability to store and retrieve information from previous time steps through a set of gated units called “cells.” These cells can selectively remember or forget information based on the input data, allowing the network to learn complex patterns and relationships within sequences.
One of the main advantages of LSTM networks is their ability to handle variable-length sequences. Traditional RNNs struggle with sequences of varying lengths, as they have a fixed-size hidden state that needs to be updated at each time step. LSTM networks, on the other hand, can dynamically adapt their hidden state based on the length of the input sequence, making them more flexible and robust for sequence prediction tasks.
Another key feature of LSTM networks is their ability to learn from both short-term and long-term dependencies in the data. The forget gate mechanism allows the network to selectively remember or forget information from previous time steps, enabling it to capture patterns that occur over long periods of time. This makes LSTM networks particularly effective for tasks that involve complex temporal relationships, such as speech recognition and language modeling.
In recent years, LSTM networks have been applied to a wide range of sequence prediction tasks with impressive results. They have been used to improve speech recognition systems, predict stock prices, generate text, and even compose music. Their ability to capture long-term dependencies in the data has made them a popular choice for researchers and practitioners working on sequence prediction problems.
Overall, LSTM networks have revolutionized the field of sequence prediction by providing a powerful and flexible tool for capturing complex temporal relationships in data. Their ability to handle variable-length sequences, learn from both short-term and long-term dependencies, and effectively model long-range interactions make them a valuable asset in a wide range of applications. As researchers continue to explore the capabilities of LSTM networks, we can expect to see even more groundbreaking advancements in the field of sequence prediction.
#LSTM #Networks #Revolutionizing #Sequence #Prediction,lstm
Enhancing Sequence Modeling with Recurrent Neural Networks: A Deep Dive into Gated Units
Recurrent Neural Networks (RNNs) have gained significant popularity in recent years for their ability to effectively model sequential data. However, traditional RNNs have limitations in capturing long-range dependencies in sequences, which can lead to difficulties in learning complex patterns.To address this issue, researchers have introduced a new type of architecture called Gated Recurrent Units (GRUs) and Long Short-Term Memory (LSTM) units, which are designed to enhance the performance of sequence modeling tasks. These gated units are equipped with mechanisms that allow them to selectively update and forget information, enabling them to better retain relevant information over long sequences.
In this article, we will take a deep dive into gated units and explore how they can improve the performance of sequence modeling tasks. We will specifically focus on GRUs, which are simpler and more efficient than LSTMs while still achieving comparable performance.
One of the key advantages of GRUs is their ability to capture long-range dependencies in sequences more effectively than traditional RNNs. This is achieved through the use of a reset gate and an update gate, which allow the model to selectively update and forget information at each time step. By doing so, the model can better retain important information over long sequences, leading to improved performance on tasks such as language modeling, machine translation, and speech recognition.
Another advantage of GRUs is their computational efficiency. Unlike LSTMs, which have separate mechanisms for updating and forgetting information, GRUs use a single gate to control both processes. This simplifies the architecture and reduces the number of parameters, making GRUs easier to train and more computationally efficient.
In addition to their performance and efficiency advantages, GRUs are also more robust to vanishing gradient problems, which can occur when training deep neural networks on long sequences. The gated mechanisms in GRUs help to mitigate this issue by allowing the model to selectively update and forget information, preventing gradients from vanishing or exploding during training.
In conclusion, gated units such as GRUs are a powerful tool for enhancing sequence modeling tasks. Their ability to capture long-range dependencies, computational efficiency, and robustness to vanishing gradient problems make them a valuable addition to the deep learning toolbox. By incorporating gated units into RNN architectures, researchers and practitioners can improve the performance of sequence modeling tasks and unlock new capabilities in natural language processing, speech recognition, and other domains.
#Enhancing #Sequence #Modeling #Recurrent #Neural #Networks #Deep #Dive #Gated #Units,recurrent neural networks: from simple to gated architectures
Building Advanced Sequence Models with Gated Architectures
In recent years, advanced sequence models with gated architectures have become increasingly popular in the field of machine learning. These models, which include Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU), have shown remarkable performance in tasks such as language modeling, machine translation, and speech recognition.One of the key features of gated architectures is their ability to capture long-range dependencies in sequential data. Traditional recurrent neural networks (RNNs) often struggle with this task due to the vanishing gradient problem, which leads to difficulties in learning long-term dependencies. Gated architectures address this issue by introducing gating mechanisms that regulate the flow of information through the network.
LSTM, one of the most well-known gated architectures, consists of three gates: the input gate, forget gate, and output gate. These gates control the flow of information by selectively updating the cell state and hidden state at each time step. This allows LSTM to remember important information over long sequences and make more accurate predictions.
GRU, on the other hand, simplifies the architecture of LSTM by combining the input and forget gates into a single update gate. This reduces the number of parameters in the model and makes it more computationally efficient. Despite its simpler design, GRU has been shown to perform on par with LSTM in many sequence modeling tasks.
Building advanced sequence models with gated architectures requires careful design and tuning of hyperparameters. Researchers and practitioners need to consider factors such as the number of layers, hidden units, and learning rate to optimize the performance of the model. Additionally, training large-scale sequence models with gated architectures can be computationally intensive, requiring powerful hardware such as GPUs or TPUs.
In conclusion, gated architectures have revolutionized the field of sequence modeling by enabling the capture of long-range dependencies in sequential data. LSTM and GRU have become go-to choices for tasks such as language modeling, machine translation, and speech recognition. Building advanced sequence models with gated architectures requires a deep understanding of the underlying principles and careful optimization of hyperparameters. As the field continues to evolve, we can expect further advancements in gated architectures and their applications in various domains.
#Building #Advanced #Sequence #Models #Gated #Architectures,recurrent neural networks: from simple to gated architectures
The Role of Recurrent Neural Networks in Sequence Modeling
Recurrent Neural Networks (RNNs) have become an essential tool in the field of sequence modeling. These networks have the ability to process sequential data by maintaining a memory of previous inputs, making them ideal for tasks such as language modeling, speech recognition, and time series prediction.One of the key features of RNNs is their ability to handle variable-length sequences. Unlike traditional feedforward neural networks, which process inputs in a fixed order, RNNs are able to take into account the temporal dependencies in the data. This makes them well-suited for tasks where the order of the input is important, such as predicting the next word in a sentence or generating captions for images.
In a typical RNN architecture, each neuron in the network is connected to itself, allowing information to flow from one time step to the next. This recurrent connection enables the network to learn patterns in the data and make predictions based on the context of previous inputs. This makes RNNs particularly effective for tasks that require understanding of long-term dependencies, such as machine translation or sentiment analysis.
One of the challenges of training RNNs is the issue of vanishing gradients, where the gradients become very small and prevent the network from learning long-range dependencies. To address this problem, researchers have developed variants of RNNs such as Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) networks, which are specifically designed to capture long-term dependencies in the data.
LSTM networks, for example, have an additional memory cell that allows them to store information for longer periods of time. This enables the network to learn complex patterns in the data and make more accurate predictions. GRU networks, on the other hand, use a gating mechanism to control the flow of information, making them more efficient and easier to train than traditional RNNs.
Overall, RNNs have proven to be a powerful tool for sequence modeling, with applications in a wide range of fields including natural language processing, speech recognition, and time series analysis. By capturing the temporal dependencies in the data, RNNs are able to make accurate predictions and generate meaningful outputs. As research in this area continues to advance, RNNs are likely to play an increasingly important role in shaping the future of machine learning and artificial intelligence.
#Role #Recurrent #Neural #Networks #Sequence #Modeling,rnn
Applications of Recurrent Neural Networks in Sequence Generation
Recurrent Neural Networks (RNNs) have gained significant popularity in recent years due to their ability to effectively model sequential data. One of the key applications of RNNs is in sequence generation, where the network is trained to generate a sequence of outputs based on a given input sequence.One of the most common uses of RNNs in sequence generation is in natural language processing tasks such as language modeling, text generation, and machine translation. In language modeling, RNNs are trained on a corpus of text data and learn to predict the next word in a sequence based on the previous words. This allows the network to generate coherent and contextually relevant text.
RNNs have also been successfully applied to music generation, where the network is trained on a dataset of musical sequences and learns to generate new musical compositions. By modeling the temporal dependencies in music, RNNs can create melodies that sound harmonious and follow musical conventions.
Another application of RNNs in sequence generation is in speech synthesis, where the network is trained to generate speech waveforms based on a given text input. This technology has been used to develop voice assistants and text-to-speech systems that can convert written text into natural-sounding speech.
In addition to these applications, RNNs have also been applied to the generation of time series data in fields such as finance, weather forecasting, and signal processing. By learning the underlying patterns in sequential data, RNNs can make accurate predictions and generate realistic sequences.
Overall, the applications of RNNs in sequence generation are vast and diverse, with the potential to revolutionize various fields such as natural language processing, music generation, speech synthesis, and time series analysis. As research in this area continues to advance, we can expect to see even more innovative applications of RNNs in sequence generation in the future.
#Applications #Recurrent #Neural #Networks #Sequence #Generation,rnn
A Comprehensive Guide to Building RNNs for Sequence Modeling
Recurrent Neural Networks (RNNs) have gained immense popularity in recent years due to their ability to effectively model sequential data. From natural language processing to time series forecasting, RNNs have proven to be a powerful tool for a wide range of applications. In this comprehensive guide, we will delve into the intricacies of building RNNs for sequence modeling.1. Understanding RNNs
RNNs are a type of neural network specifically designed to handle sequential data. Unlike traditional feedforward neural networks, RNNs have loops within their architecture, allowing them to retain information about previous inputs. This makes them well-suited for tasks such as language modeling, speech recognition, and sentiment analysis.
2. Building an RNN
To build an RNN, you first need to define the architecture of the network. This typically involves specifying the number of recurrent units (or cells) in the network, as well as the activation function to be used. Common choices for the activation function include the sigmoid, tanh, and ReLU functions.
3. Training an RNN
Once you have defined the architecture of your RNN, the next step is to train it on your dataset. This involves feeding the network sequences of input data and adjusting the weights of the network using backpropagation. It is important to split your dataset into training and validation sets to prevent overfitting.
4. Handling Long-Term Dependencies
One of the challenges of training RNNs is the issue of vanishing gradients, which can make it difficult for the network to learn long-term dependencies in the data. To address this, researchers have developed specialized RNN architectures such as Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) networks, which are better at capturing long-term dependencies.
5. Improving Performance
There are several techniques you can use to improve the performance of your RNN. These include using dropout regularization to prevent overfitting, tuning the learning rate of the optimizer, and experimenting with different network architectures. Additionally, you can use pre-trained embeddings to enhance the representation of your input data.
6. Evaluating Your Model
Once you have trained your RNN, it is important to evaluate its performance on a separate test set. Common metrics for evaluating sequence models include accuracy, precision, recall, and F1 score. You can also visualize the predictions of your model to gain insights into its behavior.
In conclusion, building RNNs for sequence modeling can be a challenging but rewarding endeavor. By understanding the fundamentals of RNNs, training your model effectively, and experimenting with different techniques, you can create powerful models for a wide range of applications. Keep in mind that building RNNs is an iterative process, and don’t be afraid to experiment and fine-tune your model to achieve the best results.
#Comprehensive #Guide #Building #RNNs #Sequence #Modeling,rnn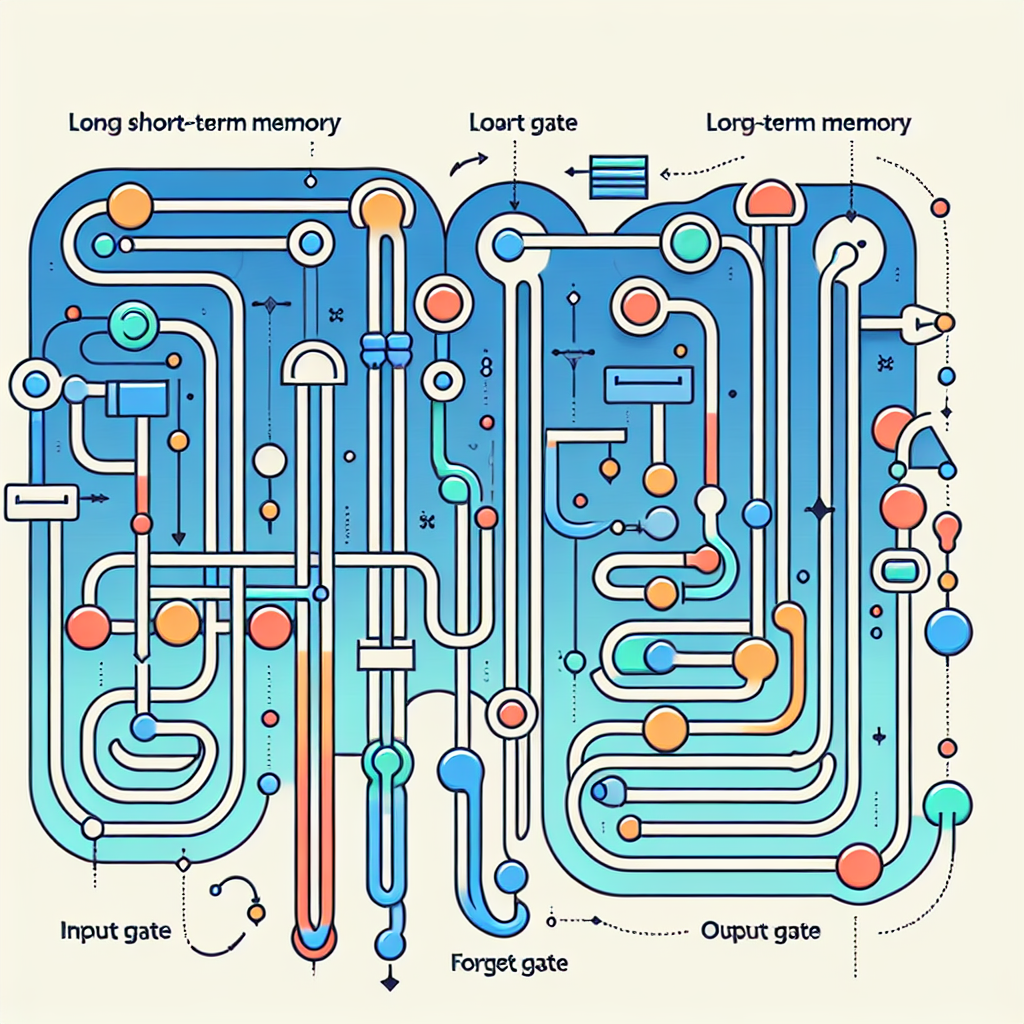
Leveraging Long Short-Term Memory (LSTM) Networks for Improved Sequence Modeling
In recent years, deep learning models have revolutionized the field of natural language processing (NLP) and sequence modeling. One of the most popular and powerful neural network architectures used for sequence modeling is the Long Short-Term Memory (LSTM) network. LSTMs are a type of recurrent neural network (RNN) that are well-suited for capturing long-term dependencies in sequential data.LSTMs were introduced by Hochreiter and Schmidhuber in 1997 and have since become a key building block in many state-of-the-art NLP models. Unlike traditional RNNs, LSTMs have a more complex architecture that includes a series of gates that control the flow of information through the network. This allows LSTMs to effectively capture long-range dependencies in sequential data, making them ideal for tasks such as language modeling, speech recognition, and machine translation.
One of the key advantages of LSTMs is their ability to remember information over long periods of time. This is achieved through the use of a memory cell that can retain information over multiple time steps, allowing the network to learn complex patterns in sequential data. This makes LSTMs particularly effective for tasks that require modeling long-range dependencies, such as predicting the next word in a sentence or generating text.
In recent years, researchers have been exploring ways to improve the performance of LSTMs for sequence modeling tasks. One approach that has shown promise is the use of attention mechanisms, which allow the network to focus on specific parts of the input sequence when making predictions. By incorporating attention mechanisms into LSTMs, researchers have been able to achieve state-of-the-art results on tasks such as machine translation and text generation.
Another area of research that has shown promise is the use of pre-trained language models to initialize the weights of LSTM networks. By leveraging large-scale language models such as BERT or GPT-3, researchers have been able to achieve significant improvements in performance on a wide range of NLP tasks. By fine-tuning these pre-trained models on specific tasks using LSTM networks, researchers have been able to achieve even better results, demonstrating the power of combining different neural network architectures for improved sequence modeling.
Overall, LSTM networks have proven to be a powerful tool for sequence modeling tasks in NLP. By leveraging their ability to capture long-range dependencies and incorporating recent advances in deep learning research, researchers have been able to achieve impressive results on a wide range of tasks. As the field of deep learning continues to evolve, it is likely that LSTM networks will remain a key building block for future advances in sequence modeling and NLP.
#Leveraging #Long #ShortTerm #Memory #LSTM #Networks #Improved #Sequence #Modeling,recurrent neural networks: from simple to gated architectures
